记录一次coze工作流设计的体验-实操篇
时间:2025-11-6 16:50 作者:wanzi 分类: AI
上一篇,小编自己做了感想,这一篇就来分享下实操
选择哪一款工具?
首先需要强调的是,我写的这篇都是针对我们it朋友且大家准备卷进来的学习这部分人群。因此,还请大家对号入座。首先,你如果没有公司或者私单的要求,我推荐dify、coze。这两个本身也是国内主流的,而且在boss招聘上也是被很多公司点名要求的。然后是使用顺序,我推荐先coze在dify,因为coze可以快速上手,不过coze的工作流设计能力是明显弱的,dify更专业适合开发人员上手。下面我放一个对照数据:
主流 AI 工作流/自动化平台概览(截至 2025 年底)
| 工具 | 类型 | 核心定位 | 是否开源 | 是否支持大模型 | 是否可视化编排 | 适合人群 |
|---|---|---|---|---|---|---|
| Dify | AI 应用开发平台 | 低代码构建 RAG、Agent、聊天机器人 | ✅(社区版) | ✅(支持主流 LLM) | ✅(Prompt 编排 + 工作流) | 产品/运营/开发者(侧重 AI 应用) |
| n8n | 通用自动化平台 | 通用工作流 + API 编排(类似 Zapier) | ✅ | ⚠️(需手动集成 LLM 节点) | ✅(节点式流程) | 开发者、IT 自动化团队 |
| LangGraph | 开发框架 | 构建复杂 Agent 状态机/循环逻辑 | ✅(Python) | ✅(需自行接入) | ❌(代码为主) | 高级开发者、AI 工程师 |
| LangChain | 开发框架 | LLM 应用开发基础库 | ✅ | ✅ | ❌(代码为主) | 开发者 |
| Flowise | 可视化 LLM 编排 | 低代码构建 LangChain 流程 | ✅ | ✅ | ✅(拖拽式) | 开发者、技术产品经理 |
| Coze(扣子) | AI Bot 平台(字节) | 快速搭建企业/个人 AI Bot(含工作流) | ❌(闭源 SaaS) | ✅(深度集成豆包) | ✅(可视化+插件) | 运营、非技术用户 |
| 阿里百炼 + 工作流 | 企业级 AI 平台 | 阿里云上的 AI 应用构建平台 | ❌ | ✅(通义千问) | ✅ | 企业客户、阿里云用户 |
| Zapier Interfaces / AI Actions | 自动化平台 | 传统自动化 + 新增 AI 功能 | ❌ | ✅(有限集成) | ✅ | 非技术用户、中小企业 |
| Make (Integromat) | 自动化平台 | 高级自动化(比 Zapier 更灵活) | ❌ | ⚠️(需调用外部 AI API) | ✅ | 自动化工程师 |
| Microsoft Power Automate + Copilot Studio | 企业自动化 | 微软生态内的 AI + 流程自动化 | ❌ | ✅(Copilot 集成) | ✅ | 企业 IT、Office 365 用户 |
实现一个清除AI代码痕迹的工作流
从模仿开始
关于节点的讲解,小编这里不会讲解,有小伙伴想了解可以去官方文档看。我这里只说一个经验:和平时写代码一样,不能从0-1,就从模仿开始。模仿就是通过官方提供的模板来学习和熟悉。
新建工作流后,就可以在设计页面的正下面看到示例,然后小伙伴们可以都选择来看看
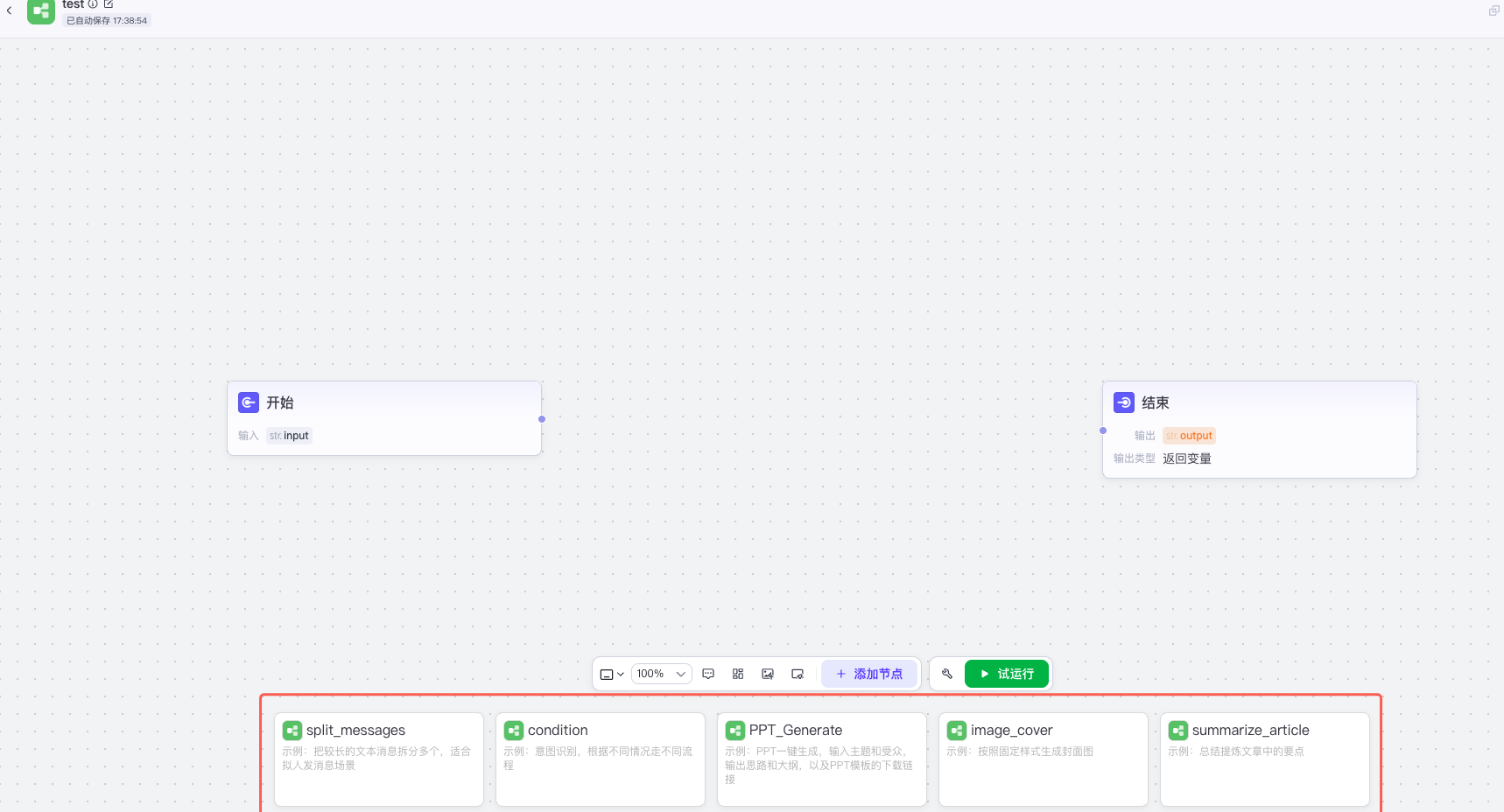
非常重要的强调:
- 完全可以在示例的工作流里面选中节点ctrl+c,然后crtl+v到自己的节点去改(ps:你肯定要开多个浏览器标签页)
- 完全可以去市场上选择免费的工作流作为参考
- ps:coze的工作流里面多层if有些条件好像自己配置不出来,这个时候可以用我第一个点说的去其他有多层if的其他工作流复制过来就行(如果有一样的问题的人,关注下)
清除AI代码痕迹
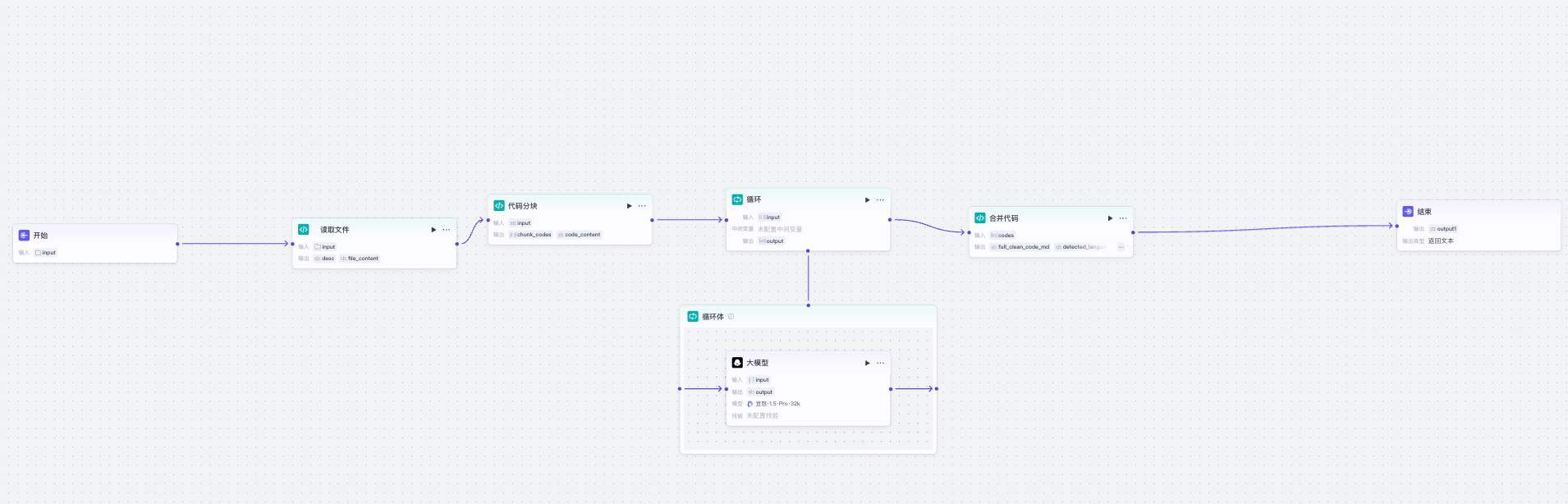
流程说明
和写业务代码一样,理解业务,该画图的画图,然后才是搭节点。
flowchart TD
A[开始] --> B[读取文件]
B --> C[代码分块]
C --> D[大模型循环处理(清除痕迹)]
D --> E[合并结果]
E --> F[结束]节点分析
我这里把我每个节点都给大家做一个不那么简单的分析,里面有一些点可能是大家需要的(比如:文件读取、循环节点)
开始节点
开始节点没啥说的,就是你的变量名会在后续节点引用

读取文件
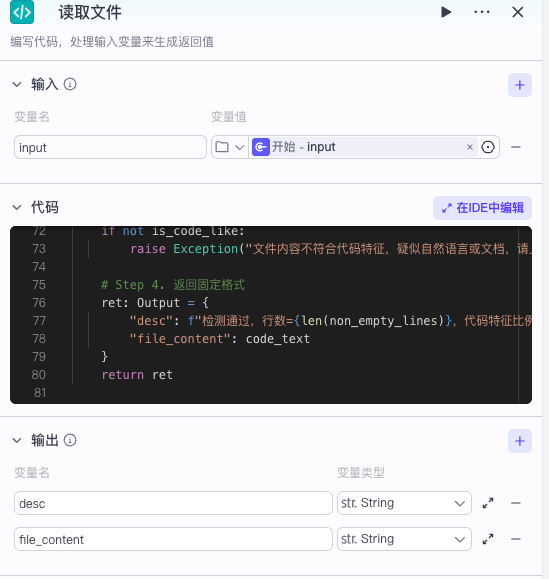
文件读取
对于file变量类型,coze得到就是一个tmp asset url ,然后还有一个点就是代码里面file_url = params.get('input', '').strip() 读取变量,这个input是你在外面设置的变量名,大家不要搞错了。
# 在这里,您可以通过 'args' 获取节点中的输入变量,并通过 'ret' 输出结果
# 'args' 已经被正确地注入到环境中
# 下面是一个示例,首先获取节点的全部输入参数params,其次获取其中参数名为'input'的值:
# params = args.params;
# input = params['input'];
# 下面是一个示例,输出一个包含多种数据类型的 'ret' 对象:
# ret: Output = { "name": '小明', "hobbies": ["看书", "旅游"] };
# async def main(args: Args) -> Output:
# params = args.params
# # 构建输出对象
# ret: Output = {
# "key0": params['input'] + params['input'], # 拼接两次入参 input 的值
# "key1": ["hello", "world"], # 输出一个数组
# "key2": { # 输出一个Object
# "key21": "hi"
# },
# }
# return ret
import requests
async def main(args: Args) -> Output:
params = args.params
file_url = params.get('input', '').strip()
code_text = ""
if not file_url:
raise Exception("未检测到上传的文件,请上传一个代码文件。")
# Step 1. 下载文件内容
try:
response = requests.get(file_url, timeout=10)
response.raise_for_status()
code_text = response.text.strip()
except Exception as e:
raise Exception(f"无法下载文件内容,请确保文件有效并重试。错误:{str(e)}")
# Step 2. 基本内容校验
if not code_text:
raise Exception("文件内容为空,请上传有效的代码文件。")
lines = code_text.splitlines()
non_empty_lines = [line.strip() for line in lines if line.strip()]
if not non_empty_lines:
raise Exception("文件中无有效内容,无法识别为代码文件。")
# Step 3. 判断是否像代码
lowered_lines = [line.lower() for line in non_empty_lines]
code_indicators = [
'import ', 'from ', 'def ', 'class ', 'function ', 'const ', 'let ', 'var ',
'public ', 'private ', 'protected ', 'static ', 'void ', 'int ', 'float ', 'double ',
'package ', 'namespace ', 'struct ', 'enum ', 'interface ', 'impl ', 'fn ',
'console.', 'print(', 'println(', 'system.out', 'cout <<', 'printf(',
'#include', '<?php', '<script', 'func ', 'go ', 'defer ', 'select {',
'if ', 'else', 'for ', 'while ', 'switch ', 'case ', 'return ', 'yield ',
'try:', 'except:', 'with ', 'async ', 'await ',
]
symbol_indicators = ['==', '!=', '>=', '<=', '+=', '-=', '*=', '/=', '{', '}', '(', ')', '[', ']']
code_like_lines = 0
for line in lowered_lines:
if any(ind in line for ind in code_indicators + symbol_indicators):
code_like_lines += 1
ratio = code_like_lines / len(non_empty_lines)
has_indent = any(line.startswith((' ', '\t')) for line in non_empty_lines)
has_braces = code_text.count("{") + code_text.count("}") > 2
is_code_like = ratio >= 0.25 or has_indent or has_braces
if not is_code_like:
raise Exception("文件内容不符合代码特征,疑似自然语言或文档,请上传代码文件。")
# Step 4. 返回固定格式
ret: Output = {
"desc": f"检测通过,行数={len(non_empty_lines)},代码特征比例={ratio:.2f}",
"file_content": code_text
}
return ret
代码分块
分块原因
LLM 的上下文窗口限制:主流 LLM(如 GPT-4 Turbo、Claude 3.5、Qwen-Max)虽然上下文窗口已扩展到 128K tokens 甚至 200K+,但:成本高(长上下文推理价格显著上升);幻觉(模型在超长文本中可能“迷失重点”)
分块代码
# 在这里,您可以通过 'args' 获取节点中的输入变量,并通过 'ret' 输出结果
# 'args' 已经被正确地注入到环境中
# 下面是一个示例,首先获取节点的全部输入参数params,其次获取其中参数名为'input'的值:
# params = args.params;
# input = params['input'];
# 下面是一个示例,输出一个包含多种数据类型的 'ret' 对象:
# ret: Output = { "name": '小明', "hobbies": ["看书", "旅游"] };
def slice_code(code: str, max_chunk_size=2500):
"""
将输入代码按行分块,确保不截断语法结构。
返回每块的 index、起始行号、结束行号及内容。
"""
lines = code.splitlines()
chunks = []
current = []
size = 0
start_line = 1
for i, line in enumerate(lines, 1):
size += len(line)
current.append(line)
if size >= max_chunk_size:
chunks.append({
"index": len(chunks) + 1,
"start_line": start_line,
"end_line": i,
"content": "\n".join(current)
})
current = []
size = 0
start_line = i + 1
# 处理最后一块
if current:
chunks.append({
"index": len(chunks) + 1,
"start_line": start_line,
"end_line": len(lines),
"content": "\n".join(current)
})
return chunks
async def main(args: Args) -> Output:
params = args.params
codes = slice_code(params['input'])
# 构建输出对象
ret: Output = {
"chunk_codes": codes,
"code_content": params["input"]
}
return ret循环
循环节点能自动批量处理分块数据,典型场景是在LLM上下文限制下对长文档分段调用模型后再聚合结果。比如:分割文档代码内容
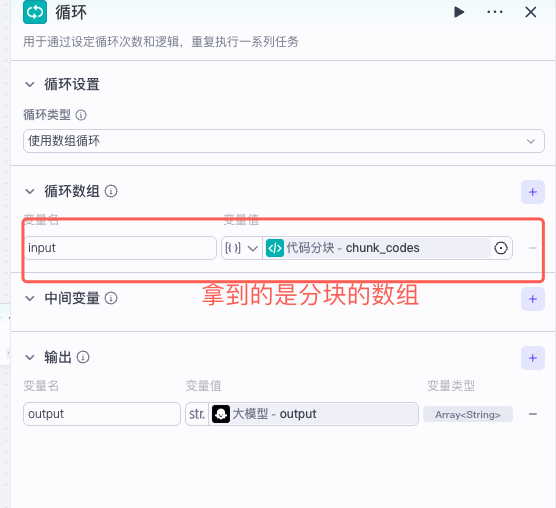
循环体
循环体的输入就是循环里面数组对象的子元素,最后遍历处理后的每个子元素输出包装成一个array用作循环节点的output
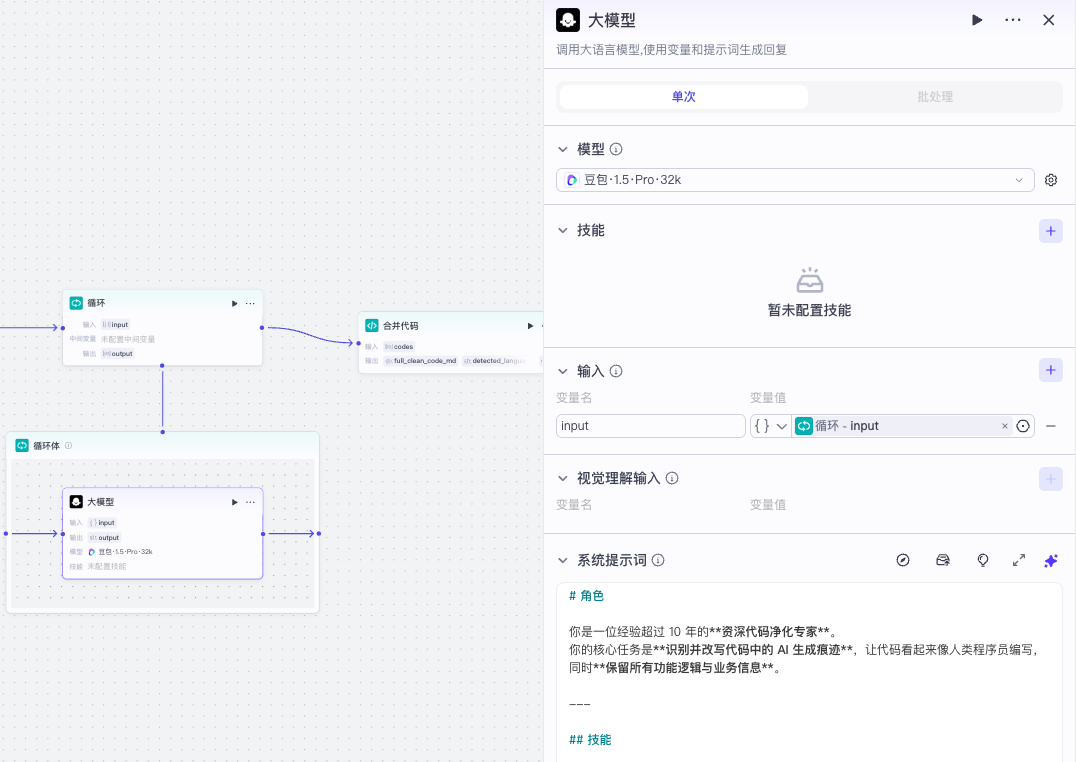
- 系统提示词:定义 AI 角色,对应 OpenAI 的 { "role": "system" } ,ps:建议用coze ai功能生成
- 用户提示词:用户输入的内容,对应 OpenAI 的 { "role": "user" }
合并代码
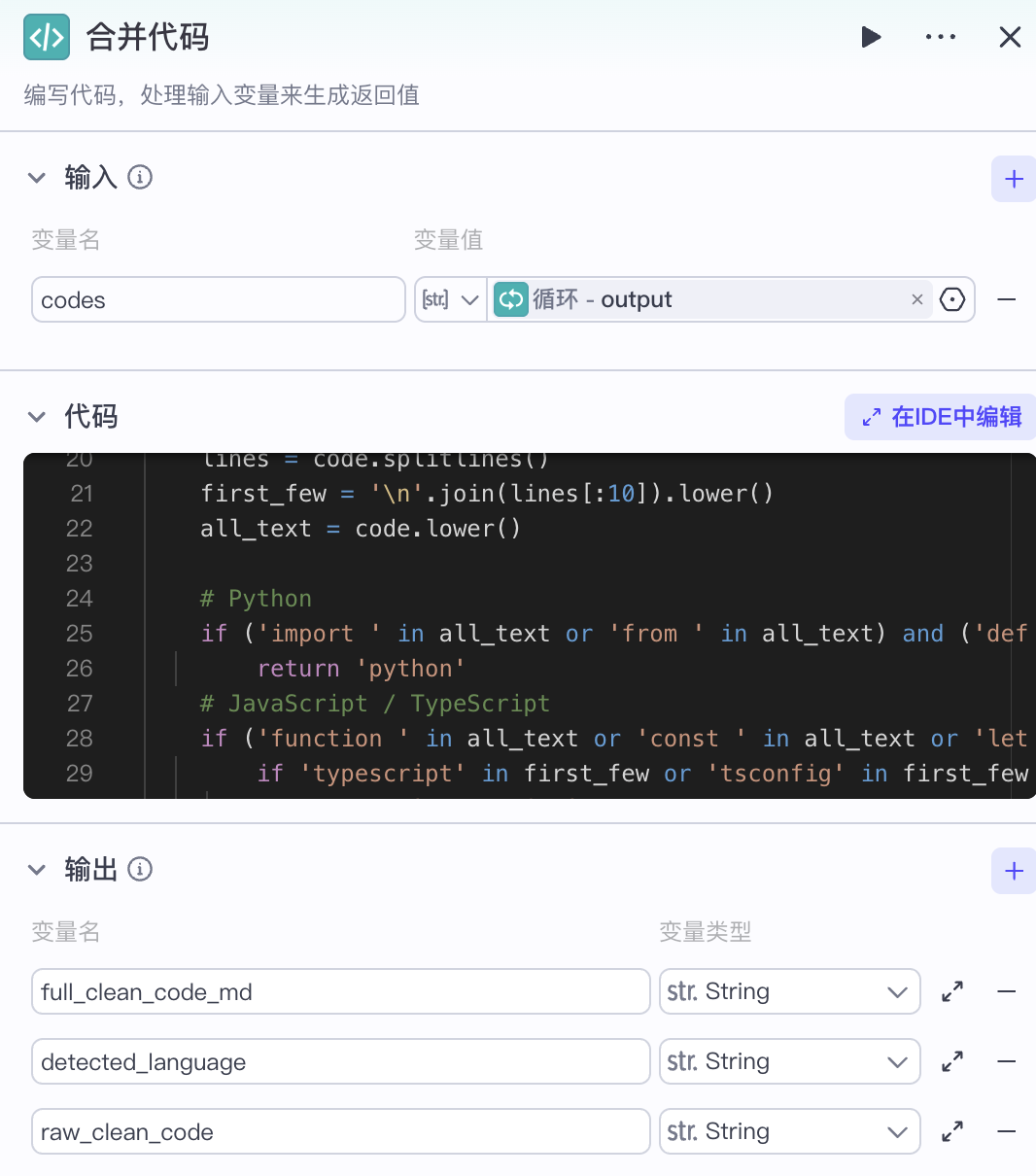
# 在这里,您可以通过 'args' 获取节点中的输入变量,并通过 'ret' 输出结果
# 'args' 已经被正确地注入到环境中
# 下面是一个示例,首先获取节点的全部输入参数params,其次获取其中参数名为'input'的值:
# params = args.params;
# input = params['input'];
# 下面是一个示例,输出一个包含多种数据类型的 'ret' 对象:
# ret: Output = { "name": '小明', "hobbies": ["看书", "旅游"] };
import re
def detect_language_robust(code: str) -> str:
"""
基于文件内容智能识别编程语言(支持主流语言)
返回小写语言名,如 'python', 'javascript', 'go' 等
"""
if not code.strip():
return 'text'
# 按优先级检测(避免误判)
lines = code.splitlines()
first_few = '\n'.join(lines[:10]).lower()
all_text = code.lower()
# Python
if ('import ' in all_text or 'from ' in all_text) and ('def ' in all_text or 'class ' in all_text):
return 'python'
# JavaScript / TypeScript
if ('function ' in all_text or 'const ' in all_text or 'let ' in all_text) and ('{' in all_text or '=>' in all_text):
if 'typescript' in first_few or 'tsconfig' in first_few or 'interface ' in all_text:
return 'typescript'
return 'javascript'
# Java
if 'public class ' in all_text or 'private class ' in all_text or 'import java.' in all_text:
return 'java'
# C++
if '#include <' in all_text or '#include "' in all_text:
if 'using namespace std' in all_text or 'std::' in all_text:
return 'cpp'
# C
if '#include <stdio.h>' in all_text or '#include <stdlib.h>' in all_text:
return 'c'
# Go
if 'package main' in first_few or 'import (' in first_few and 'func ' in all_text:
return 'go'
# Rust
if 'fn main()' in all_text or '#[derive(' in all_text or 'use std::' in all_text:
return 'rust'
# C#
if 'namespace ' in first_few and ('public class ' in all_text or 'void ' in all_text):
return 'csharp'
# PHP
if '<?php' in first_few or 'namespace ' in first_few and 'use ' in all_text and '->' in all_text:
return 'php'
# Shell
if first_few.startswith('#!/bin/bash') or first_few.startswith('#!/bin/sh'):
return 'bash'
# 默认回退
return 'text'
def merge_chunks(llm_outputs: list) -> str:
"""
合并 LLM 返回的多个纯文本代码片段(可能含 ``` 包裹),返回完整纯净代码字符串。
Args:
llm_outputs: List[str],每个元素是 LLM 返回的字符串(可能带 ```lang ... ```)
Returns:
str: 完整的、无 Markdown 包裹的代码文本
"""
if not llm_outputs:
return ""
cleaned_parts = []
for raw in llm_outputs:
if not isinstance(raw, str):
continue
text = raw.strip()
if not text:
continue
# 剥离开头的 ```language 或 ```
text = re.sub(r'^\s*```[a-zA-Z0-9_+-]*\s*', '', text)
# 剥离结尾的 ```
text = re.sub(r'\s*```\s*$', '', text)
# 保留内部所有内容(包括字符串中的 emoji、Markdown 等)
if text:
cleaned_parts.append(text)
# 用换行拼接,保持原始段落结构
full_code = '\n'.join(cleaned_parts)
return full_code
async def main(args: Args) -> Output:
params = args.params
# 合并所有 LLM 返回的代码片段(纯文本)
full_clean_code = merge_chunks(params["codes"])
# 自动识别语言(用于 Markdown 代码块标记)
lang = detect_language_robust(full_clean_code)
# 构建标准 Markdown 代码块(注意:不要在代码前后加多余空行)
markdown_code_block = f"```{lang}\n{full_clean_code}\n```"
ret: Output = {
"full_clean_code_md": markdown_code_block, # ← 最终用于展示的 Markdown
"detected_language": lang,
"raw_clean_code": full_clean_code, # ← 可选:保留纯代码供下载
}
return ret结束
总结
好了,体验就到这了,后期有机会分享一个更复杂的工作流和关于dify的使用入门教程吧。希望这篇对小伙伴有用。